DSPy: Revolutionizing Complex System Development with Language Models
 Traditionally, building a complex system with LMs involves a multi-step process that can feel like navigating a labyrinth. Developers must break down the problem into manageable steps, fine-tune prompts and models through trial and error, and constantly adjust to ensure each component interacts seamlessly. This painstaking process is not only time-consuming but also fraught with potential for errors, requiring frequent revisions that can quickly become overwhelming.
Traditionally, building a complex system with LMs involves a multi-step process that can feel like navigating a labyrinth. Developers must break down the problem into manageable steps, fine-tune prompts and models through trial and error, and constantly adjust to ensure each component interacts seamlessly. This painstaking process is not only time-consuming but also fraught with potential for errors, requiring frequent revisions that can quickly become overwhelming.
In this post we will explore the python library DSPy. DSPy is an innovative approach designed to enhance the capabilities of frozen language models (LM) and retrieval models (RM) by enabling them to work in concert to tackle complex, knowledge intensive tasks.
DSPy consists of a number of simple composable functions for implementing in-context learning (ICL) systems as deliberate programs – instead of end-task prompts—for solving knowledge intensive tasks. DSPy is the current implementation of this ICL Compiler
Introducing DSPy:
DSPy revolutionizes this process by fundamentally rethinking the relationship between the flow of a program and the parameters that guide it. It distinguishes itself by doing two critical things:
1) Modularizing System Flow: DSPy abstracts the program’s logic into discrete modules, clearly separating the algorithmic flow from the underlying parameters like LM prompts and weights. This modular approach allows for greater flexibility and reusability of components, facilitating easier updates and modifications without the need to start from scratch.
2) Introducing Powerful Optimizers: Where DSPy truly shines is in its suite of LM-driven optimizers. These advanced algorithms are designed to dynamically adjust LM prompts and weights to optimize for a specific metric, be it accuracy, efficiency, or avoiding known failure modes. Through this optimization process, DSPy can effectively “teach” both powerful and localized models (from giants like GPT-3.5 and GPT-4 to T5-base and Llama2-13b) to perform tasks with a level of reliability and quality previously unattainable.
The Result: Less Prompting, Higher Scores, Systematic Solutions
With DSPy, the days of manual prompt crafting are moving behind us. Instead, DSPy’s optimizers automatically compile the program into tailored instructions and prompts specific to each model’s needs. This shift represents a new paradigm where language models and their prompts become seamlessly integrated, optimizable elements of a larger system capable of learning and adapting from data. In essence, DSPy offers a more systematic, efficient, and scalable approach to solving complex tasks with LMs.
Practical Applications: DSPy in Action
In this example, we’ll explore how DSPy can be used to enhance the process of solving math questions from the GSM8K dataset. This dataset is a collection of grade school math problems, which presents a unique challenge for language models: not only understanding the text of the question but also performing the necessary calculations to arrive at the correct answer.
Traditional Approach Challenges:
- Crafting prompts that guide the language model to understand and solve math problems can be highly nuanced.
- Ensuring the language model consistently follows logical steps toward the correct answer requires careful prompt engineering and potentially extensive fine-tuning.
Step 1: Setting Up the Language Model
First, we configure DSPy to use a specific version of the GPT model optimized for instructions, ensuring our language model is primed for detailed, instruction-following tasks.
import dspy
# Set up the LM with GPT-3.5-turbo-instruct for detailed instruction following
turbo = dspy.OpenAI(model='gpt-3.5-turbo-instruct', max_tokens=250)
dspy.settings.configure(lm=turbo)
Step 2: Loading the Dataset
We then load the GSM8K dataset, which contains the math questions we want our model to solve.
from dspy.datasets.gsm8k import GSM8K
# Load math questions from the GSM8K dataset
gms8k = GSM8K()
trainset, devset = gms8k.train, gms8k.dev
Finally, we compile our DSPy module using optimizers that automatically adjust prompts and weights to maximize the outcome metrics such as accuracy and coherence.
Step 3: Creating the DSPy Module for Chain of Thought (CoT)
The Chain of Thought (CoT) approach involves the model generating intermediate steps leading to the final answer, mimicking how a human might solve a math problem.
class CoT(dspy.Module):
def __init__(self):
super().__init__()
self.prog = dspy.ChainOfThought("question -> answer")
def forward(self, question):
answer = self.prog(question=question)
return answer
Step 4: Optimizing with DSPy’s Teleprompt
We employ DSPy’s BootstrapFewShotWithRandomSearch optimizer to refine our CoT module. This optimizer self-generates examples and iteratively improves the model’s performance on our dataset.
from dspy.teleprompt import BootstrapFewShotWithRandomSearch
config = dict(max_bootstrapped_demos=8, max_labeled_demos=8, num_candidate_programs=10, num_threads=4)
teleprompter = BootstrapFewShotWithRandomSearch(metric=gsm8k_metric, **config)
optimized_cot = teleprompter.compile(CoT(), trainset=trainset, valset=devset)
This step is where the magic happens. The optimizer automatically adjusts the prompts and weights of our CoT module to maximize the desired outcome metrics, such as accuracy and coherence. This automation significantly reduces the need for manual fine-tuning and prompt crafting, streamlining the development process.
Step 5: Evaluating the Optimized Model
Finally, we evaluate our optimized CoT module on the development set to measure its effectiveness in solving math problems.
from dspy.evaluate import Evaluate
evaluate = Evaluate(devset=devset, metric=gsm8k_metric, num_threads=4, display_progress=True)
compiled_score = evaluate(optimized_cot)
uncompiled_score = evaluate(CoT())
This evaluation step allows us to compare the performance of our optimized CoT module with the unoptimized version, providing valuable insights into the effectiveness of our optimization process. The results?
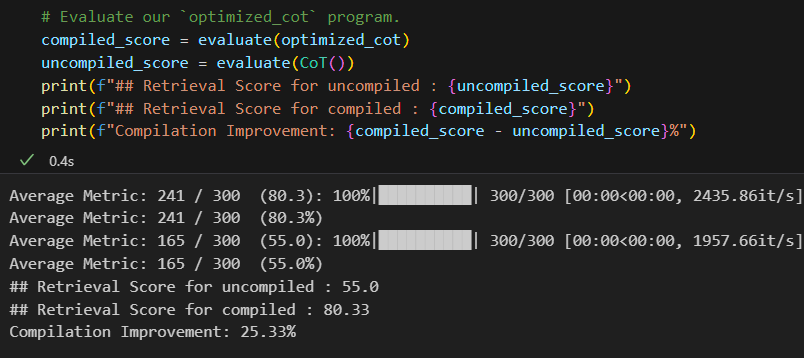
A 25.33% improvement in accuracy.
DSPy not only simplifies the current process of developing complex systems with LMs but also opens up new possibilities for innovation. By reducing the dependency on manual prompt crafting and fine-tuning, developers can focus more on the creative and strategic aspects of their projects. This shift has the potential to accelerate the development of more sophisticated and versatile systems, pushing the boundaries of what’s possible with language models.
DSPy represents a significant leap forward in the field of complex system development with language models. Its ability to automate and optimize the use of language models within these systems promises not only to streamline the development process but also to enhance the robustness and scalability of the solutions created. As we look to the future, it’s clear to us that frameworks and techniques like DSPy will play a pivotal role.
Interested in learning more about the project?
Check out Stanford’s DSPy GitHub repository or the DSPy documentation!